Проверим аналитические возможности модуля Oracle Spatial для решения маркетиновых задач.
Легенда:
Среди крупнейших сетей супермаркетов в Москве выберем две -- Пятёрочку и Седьмой континент (коллеги подсказывают, что эти две сети не похожи по формату и в реальной жизни они между собой не конкурируют, но сейчас для нас это не имеет значения -- подставив адреса магазинов других сетей мы получим реальные результаты, а это -- только пример).
Магазины этих сетей находятся в спальных районах, в окружении жилых домой.
Жителям приходится выбирать, в какой магазин идти. Скорее всего, жители пойдут в ближайший.
Но есть такие дома, которые находятся на приблизительно равном расстоянии от двух супермаркетов.
Эти жители не имеют предпочтений в выборе магазина (в нашем случае, пропустим другие детерминанты покупательского выбора), и предложив им определённые условия (скидки и пр.), можно сместить предпочтения в сторону нашего магазина.
Как мы будем их искать?
Данные импортированы с сайта GisLab http://gis-lab.info/projects/osm_dump/, когда-то Александр Рындин (Oracle, http://www.oraclegis.com/blog/?p=2629) рекомендовал этот источник как открытый
Вот результат выполнения расчёта:
Жёлтый цвет -- крупные магистрали,
Чёрный -- границы Москвы,
Синие маркеры и пунктирные окружности -- отметки магазинов Седьмой континент,
Красные маркеры и окружности -- магазины сети Пятёрочка

Вот как выглядит увеличенное изображение карты:
Не надо регулировать ваши мониторы -- круги не круглые из-за того, что их MapBuilder неправильно отображает

Ещё крупнее, со всеми номерами домов

Эта карта с номерами домов -- прямое руководство к действию. Сосредотачиваем маркетинговые усилия на этих территориях.
Легенда:
Среди крупнейших сетей супермаркетов в Москве выберем две -- Пятёрочку и Седьмой континент (коллеги подсказывают, что эти две сети не похожи по формату и в реальной жизни они между собой не конкурируют, но сейчас для нас это не имеет значения -- подставив адреса магазинов других сетей мы получим реальные результаты, а это -- только пример).
Магазины этих сетей находятся в спальных районах, в окружении жилых домой.
Жителям приходится выбирать, в какой магазин идти. Скорее всего, жители пойдут в ближайший.
Но есть такие дома, которые находятся на приблизительно равном расстоянии от двух супермаркетов.
Эти жители не имеют предпочтений в выборе магазина (в нашем случае, пропустим другие детерминанты покупательского выбора), и предложив им определённые условия (скидки и пр.), можно сместить предпочтения в сторону нашего магазина.
Как мы будем их искать?
- Найдём пары магазинов разных сетей, расположенных на расстоянии не более 2 км друг от друга.
- Определим расстояние между такими парами магазинов.
- Нарисуем на карте окружности, с центрами в каждом магазине пары и радиусом в 2 / 3 от расстояния между магазинами пары.
- Пересечение окружностей будет иметь вид "мяча для регби". Дома, находящиеся внутри этой области, равноудалены от обоих магазинов. Маркетинговые усилия нужно сосредоточить на жителях именно этих домов.
- Определим адреса домов и напечатаем карту -- рекламные листовки нужно бросать в первую очередь в почтовые ящики этих домов. Если мы располагаем базой покупателей (адреса для выданных дисконтных карт) -- то лучшие скидки предлагаем имено таким покупателям.
Данные импортированы с сайта GisLab http://gis-lab.info/projects/osm_dump/, когда-то Александр Рындин (Oracle, http://www.oraclegis.com/blog/?p=2629) рекомендовал этот источник как открытый
Вот результат выполнения расчёта:
Жёлтый цвет -- крупные магистрали,
Чёрный -- границы Москвы,
Синие маркеры и пунктирные окружности -- отметки магазинов Седьмой континент,
Красные маркеры и окружности -- магазины сети Пятёрочка
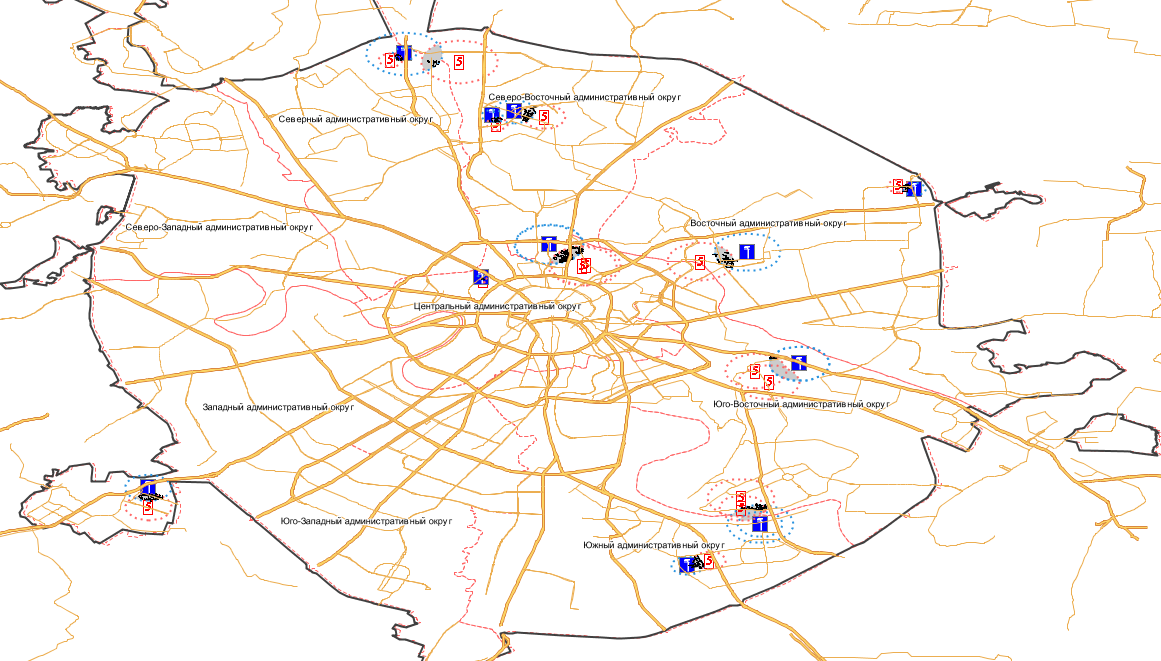
Вот как выглядит увеличенное изображение карты:
Не надо регулировать ваши мониторы -- круги не круглые из-за того, что их MapBuilder неправильно отображает
Ещё крупнее, со всеми номерами домов

Эта карта с номерами домов -- прямое руководство к действию. Сосредотачиваем маркетинговые усилия на этих территориях.